Project Index
Research Projects
A focused view of my work in computer vision, multimodal understanding, and segmentation, with an emphasis on models that connect visual structure, language, and physically grounded perception.
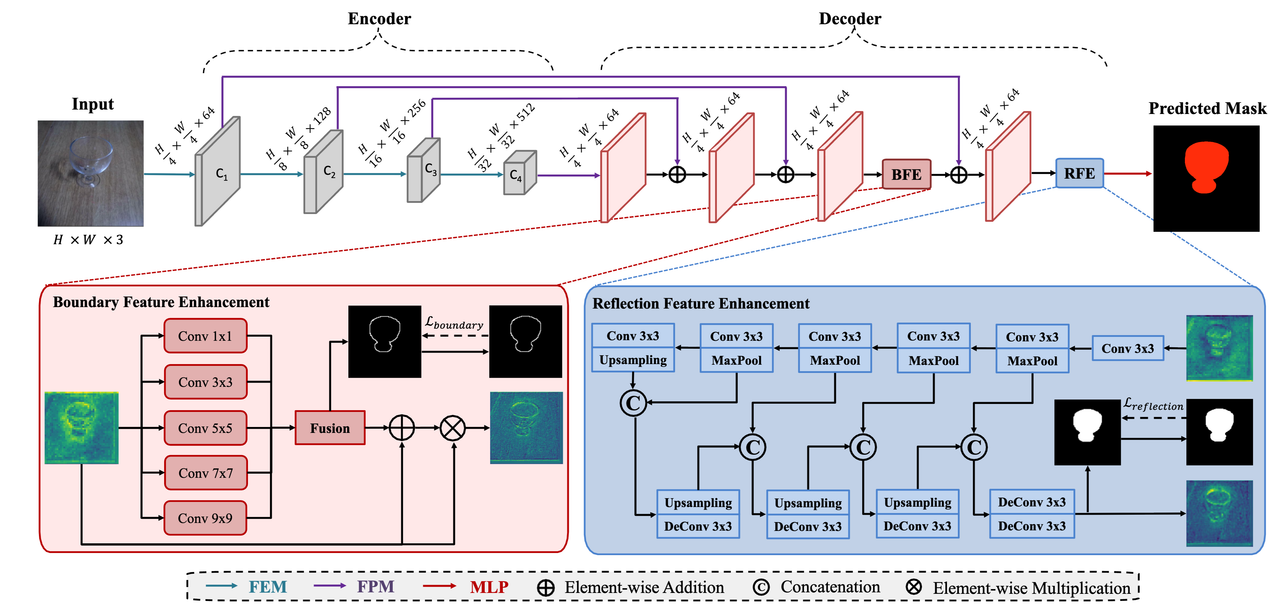
Power of Boundary and Reflection: Semantic Transparent Object Segmentation using Pyramid Vision Transformer with Transparent Cues
TransCues introduces an efficient transformer-based segmentation architecture capable of handling transparent, reflective, and general objects. By proposing Boundary Feature Enhancement (BFE) and Reflection Feature Enhancement (RFE), we enable the model to better capture subtle details in both glass and non-glass regions, resulting in more accurate and robust segmentation.
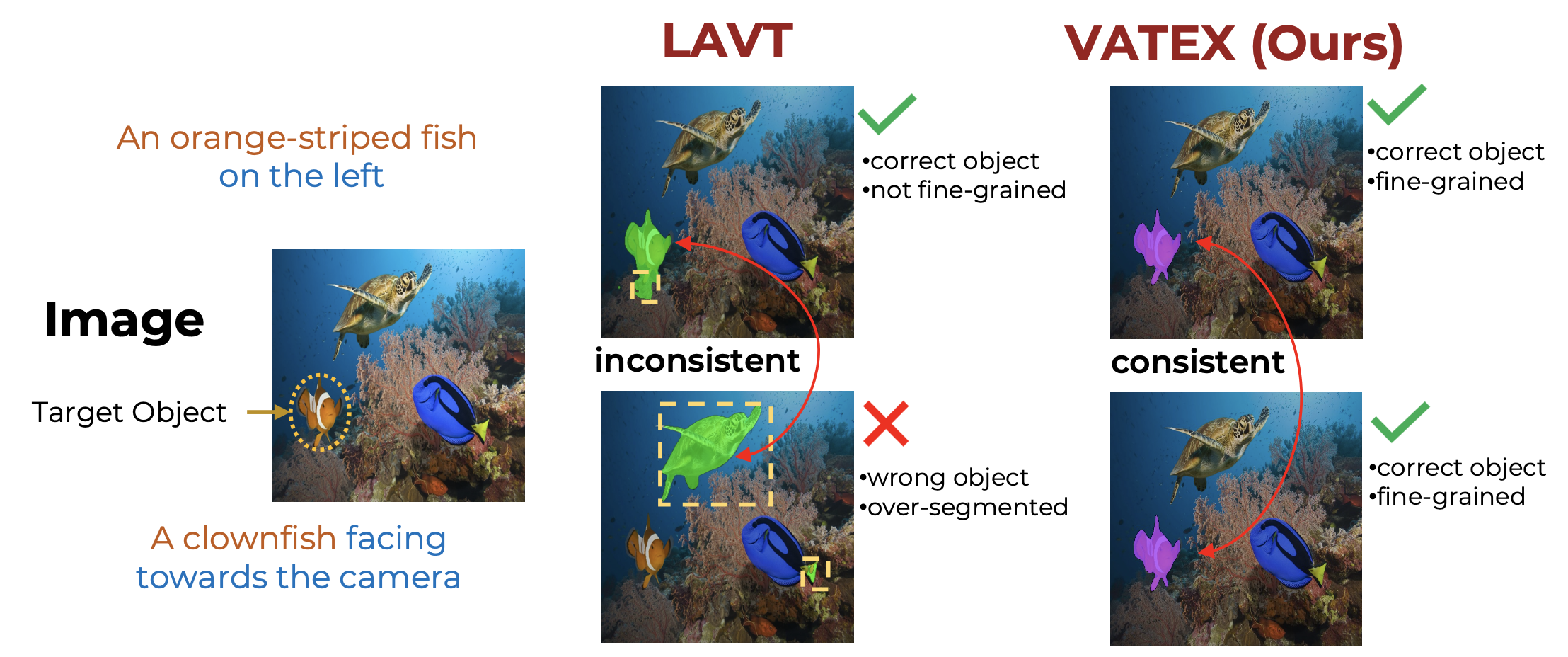
Vision-Aware Text Features in Referring Expression Segmentation: From Object Understanding to Context Understanding
VATEX is a novel method for referring image segmentation that leverages vision-aware text features to improve text understanding. By decomposing language cues into object and context understanding, the model can better localize objects and interpret complex sentences, leading to significant performance gains.
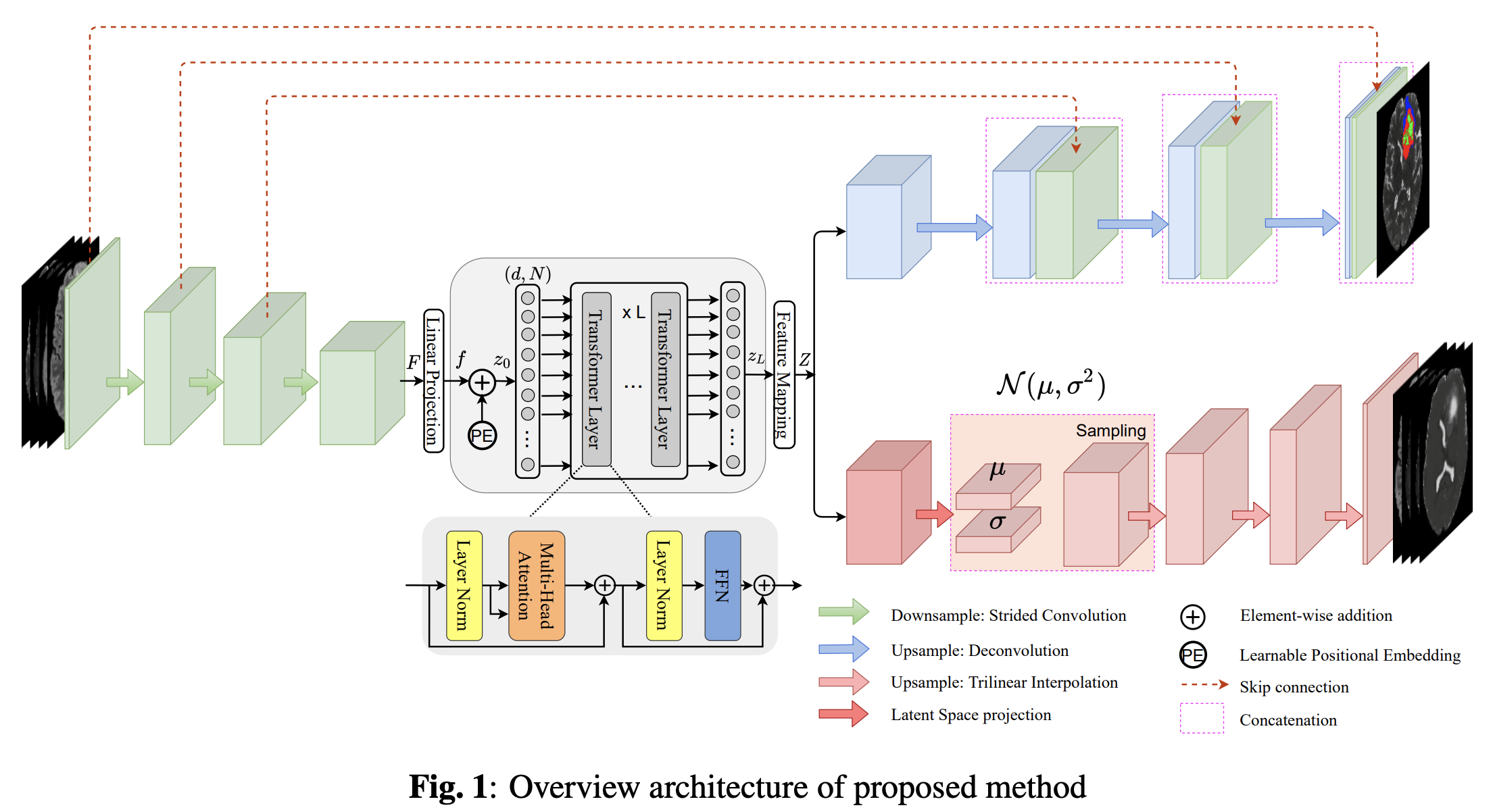
SegTransVAE: Hybrid CNN - Transformer with Regularization for medical image segmentation
SegTransVAE is the first work exploiting the hybrid architecture between CNN, Transformers with the Variational Autoencoder (VAE) branch to the network to reconstruct the input images jointly with segmentation.